Installation
if(!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("planet")Cell composition
To infer cell composition on placental villi DNAm samples, we can
need to use placental reference cpgs (Yuan
2021). These are provided in this package as
plCellCpGsThird and plCellCpGsFirst for third
trimester (term) and first trimester samples, respectively.
In this example we are using term villi DNAm data, so we first load
the reference cpgs plCellCpGsThird. This is a data frame of
600 cpgs, with mean methylation levels for each cell type.
# cell deconvolution packages
library(minfi)
library(EpiDISH)
# data wrangling and plotting
library(dplyr)
library(ggplot2)
library(tidyr)
library(planet)
# load example data
data("plBetas")
data("plCellCpGsThird")
head(plCellCpGsThird)## Trophoblasts Stromal Hofbauer Endothelial nRBC
## cg10590657 0.1014098 0.9345796 0.8655285 0.8963641 0.8448382
## cg14923398 0.1282030 0.8902107 0.9036769 0.9383641 0.9508709
## cg05348366 0.1305697 0.9519820 0.8803082 0.9065136 0.9278057
## cg17907628 0.1215249 0.9278777 0.8727841 0.8914412 0.9143601
## cg26799656 0.1259953 0.9482014 0.8803863 0.8791004 0.9010419
## cg11862144 0.1561991 0.9430855 0.9114967 0.9341671 0.9647331
## Syncytiotrophoblast
## cg10590657 0.05460441
## cg14923398 0.05383193
## cg05348366 0.06546727
## cg17907628 0.05325227
## cg26799656 0.06823985
## cg11862144 0.06044207After our reference cpg data is loaded, we can estimate cell composition by applying either the Constrained Projection approach implemented by the R packages minfi or EpiDISH, or a non-constrained approach by EpiDish. I demonstrate how to do both.
Minfi
houseman_estimates <- minfi:::projectCellType(
plBetas[rownames(plCellCpGsThird), ],
plCellCpGsThird,
lessThanOne = FALSE
)
head(houseman_estimates)## Trophoblasts Stromal Hofbauer Endothelial nRBC
## GSM1944936 0.1091279 0.04891919 0.000000e+00 0.08983998 0.05294062
## GSM1944939 0.2299918 0.00000000 -1.806592e-19 0.07888007 0.03374149
## GSM1944942 0.1934287 0.03483540 0.000000e+00 0.09260353 0.02929310
## GSM1944944 0.2239896 0.06249135 1.608645e-03 0.11040693 0.04447951
## GSM1944946 0.1894152 0.07935955 0.000000e+00 0.10587439 0.05407587
## GSM1944948 0.2045124 0.07657717 0.000000e+00 0.09871149 0.02269798
## Syncytiotrophoblast
## GSM1944936 0.6979477
## GSM1944939 0.6377822
## GSM1944942 0.6350506
## GSM1944944 0.5467642
## GSM1944946 0.6022329
## GSM1944948 0.6085825EpiDISH
# robust partial correlations
epidish_RPC <- epidish(
beta.m = plBetas[rownames(plCellCpGsThird), ],
ref.m = plCellCpGsThird,
method = "RPC"
)
# CIBERSORT
epidish_CBS <- epidish(
beta.m = plBetas[rownames(plCellCpGsThird), ],
ref.m = plCellCpGsThird,
method = "CBS"
)## 1## 2## 3
# constrained projection (houseman 2012)
epidish_CP <- epidish(
beta.m = plBetas[rownames(plCellCpGsThird), ],
ref.m = plCellCpGsThird,
method = "CP"
)## 1## 2## 3## 4## 5## 6## 7## 8## 9## 10## 11## 12## 13## 14## 15## 16## 17## 18## 19## 20## 21## 22## 23## 24Compare
Below, I demonstrate how we can visually compare the different cell composition estimates.
data("plColors")
# bind estimate data frames and reshape for plotting
bind_rows(
houseman_estimates %>% as.data.frame() %>% mutate(algorithm = "CP (Houseman)"),
epidish_RPC$estF %>% as.data.frame() %>% mutate(algorithm = "RPC"),
epidish_CBS$estF %>% as.data.frame() %>% mutate(algorithm = "CBS"),
epidish_CP$estF %>% as.data.frame() %>% mutate(algorithm = "CP (EpiDISH)")
) %>%
mutate(sample = rep(rownames(houseman_estimates), 4)) %>%
as_tibble() %>%
pivot_longer(
cols = -c(algorithm, sample),
names_to = "component",
values_to = "estimate"
) %>%
# relevel for plot
mutate(component = factor(component,
levels = c(
"nRBC", "Endothelial", "Hofbauer",
"Stromal", "Trophoblasts",
"Syncytiotrophoblast"
)
)) %>%
# plot
ggplot(aes(x = sample, y = estimate, fill = component)) +
geom_bar(stat = "identity") +
facet_wrap(~algorithm, ncol = 1) +
scale_fill_manual(values = plColors) +
scale_y_continuous(
limits = c(-0.1, 1.1), breaks = c(0, 0.5, 1),
labels = scales::percent
) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5)) +
coord_cartesian(ylim = c(0, 1)) +
labs(x = "", fill = "")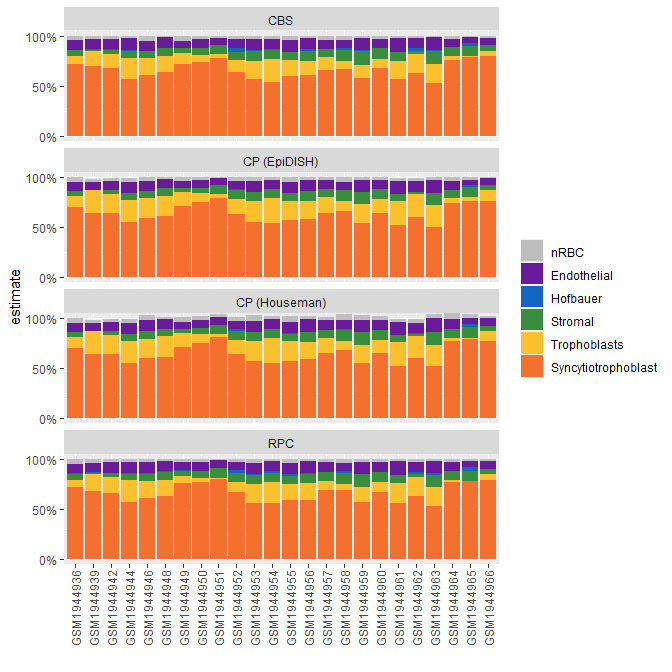
Some notes:
- Normalize your data with
minfi::preprocessNooband BMIQ - Use all cell CpGs - if some are missing, estimates may vary
- If your samples have been processed in a particular manner, (e.g. sampling from maternal side) expect cell composition to reflect that
Gestational age
Example Data
For demonstration, I use 24 samples from a placental DNAm dataset
from GEO, (GSE7519),
which contains samples collected in an Australian population. The DNA
methylation data (in betas) can be accessed with
data(plBetas) and corresponding sample information from
data(plPhenoData). Note that for demonstration purposes,
the cpgs have been filtered to a random ~10,000 CpGs, plus the CpGs used
in all of the functions from this package.
## [1] 13918 24
#> [1] 13918 24
head(plPhenoData)| sample_id | sex | disease | gestation_wk | ga_RPC | ga_CPC | ga_RRPC |
|---|---|---|---|---|---|---|
| GSM1944936 | Male | preeclampsia | 36 | 38.46528 | 38.72867 | 38.65396 |
| GSM1944939 | Male | preeclampsia | 32 | 33.09680 | 34.21252 | 32.62763 |
| GSM1944942 | Female | preeclampsia | 32 | 34.32520 | 35.09565 | 33.32502 |
| GSM1944944 | Male | preeclampsia | 35 | 35.50937 | 36.71512 | 35.51295 |
| GSM1944946 | Female | preeclampsia | 38 | 37.63910 | 37.57931 | 36.61721 |
| GSM1944948 | Female | preeclampsia | 36 | 36.77051 | 38.42632 | 36.72150 |
#> # A tibble: 6 x 7
#> sample_id sex disease gestation_wk ga_RPC ga_CPC ga_RRPC
#> <fct> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 GSM1944936 Male preeclam~ 36 38.5 38.7 38.7
#> 2 GSM1944939 Male preeclam~ 32 33.1 34.2 32.6
#> 3 GSM1944942 Fema~ preeclam~ 32 34.3 35.1 33.3
#> 4 GSM1944944 Male preeclam~ 35 35.5 36.7 35.5
#> 5 GSM1944946 Fema~ preeclam~ 38 37.6 37.6 36.6
#> 6 GSM1944948 Fema~ preeclam~ 36 36.8 38.4 36.7There are 3 gestational age clocks for placental DNA methylation data from (Lee 2019):
- Robust Placental Clock (RPC)
- Control Placental Clock (CPC)
- Refined Robust Placental Clock (RRPC)
To predict gestational, we load the example data:
-
plBetas- DNAm data for 24 placental samples -
plPhenoData- Matching sample information
Predict Gestational Age
To select the type of clock, we can specify the type
argument in predictAge.
We will apply all three clocks on this data, and add the predicted
age to the sample information data.frame, plPhenoData.
plPhenoData <- plPhenoData %>%
mutate(
ga_RPC = predictAge(plBetas, type = "RPC"),
ga_CPC = predictAge(plBetas, type = "CPC"),
ga_RRPC = predictAge(plBetas, type = "RRPC")
)## 558 of 558 predictors present.## 546 of 546 predictors present.## 395 of 395 predictors present.Note that the number of predictors (CpGs) that were used in our data are printed. It’s important to take note if a significant number of predictive CpGs are missing in your data, as this can affect the predicted gestational age accuracy.
Next, I plot the difference between predicted and reported gestational age, for each of the 3 gestational age predictors.
plPhenoData %>%
# reshape, to plot
pivot_longer(
cols = contains("ga"),
names_to = "clock_type",
names_prefix = "ga_",
values_to = "ga"
) %>%
# plot code
ggplot(aes(x = gestation_wk, y = ga, col = disease)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(~clock_type) +
theme(legend.position = "top") +
labs(x = "Reported GA (weeks)", y = "Inferred GA (weeks)", col = "")## `geom_smooth()` using formula = 'y ~ x'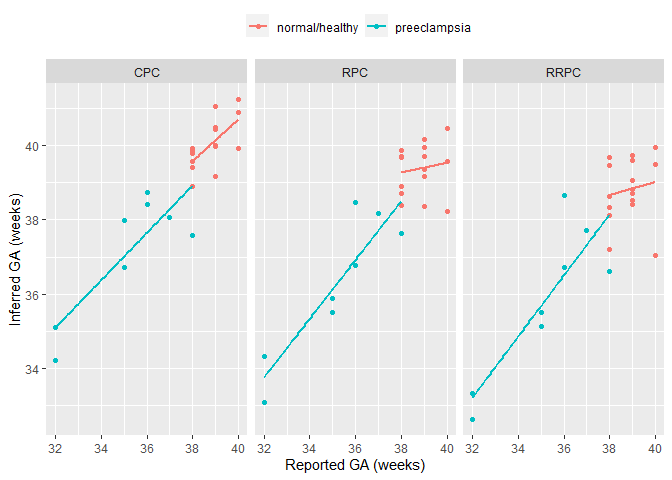
Ethnicity
Before predicting ethnicity You can ensure that you have all features
using the ethnicityCpGs vector:
## [1] TRUE
results <- predictEthnicity(plBetas)## 1860 of 1860 predictors present.| Sample_ID | Predicted_ethnicity_nothresh | Predicted_ethnicity | Prob_African | Prob_Asian | Prob_Caucasian | Highest_Prob |
|---|---|---|---|---|---|---|
| GSM1944959 | Asian | Asian | 0.0123073 | 0.9523544 | 0.0353383 | 0.9523544 |
| GSM1944960 | Caucasian | Caucasian | 0.0156961 | 0.1595213 | 0.8247827 | 0.8247827 |
| GSM1944961 | Asian | Asian | 0.0208421 | 0.8954518 | 0.0837061 | 0.8954518 |
| GSM1944962 | Caucasian | Caucasian | 0.0009276 | 0.0008801 | 0.9981923 | 0.9981923 |
| GSM1944963 | Caucasian | Caucasian | 0.0022635 | 0.0028007 | 0.9949358 | 0.9949358 |
| GSM1944964 | Caucasian | Caucasian | 0.0065973 | 0.0112013 | 0.9822014 | 0.9822014 |
| GSM1944965 | Caucasian | Caucasian | 0.0021578 | 0.0024196 | 0.9954226 | 0.9954226 |
| GSM1944966 | Caucasian | Caucasian | 0.0011397 | 0.0017651 | 0.9970952 | 0.9970952 |
predictEthnicity returns probabilities corresponding to
each ethnicity for each sample (e.g Prob_Caucasian,
Prob_African, Prob_Asian). This applies a
glmnet model described in (Yuan
2019). A final classification is determined in two ways:
Predicted_ethnicity_nothresh- returns a classification corresponding to the highest class-specific probability.Predicted_ethnicity- if the highest class-specific probability is below0.75, then the the sample is assigned anAmibiguouslabel. This threshold can be adjusted with thethresholdargument. Samples with this label might require special attention in downstream analyses.
results %>%
ggplot(aes(
x = Prob_Caucasian, y = Prob_African,
col = Predicted_ethnicity
)) +
geom_point(alpha = 0.7) +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1)) +
scale_x_continuous(labels = scales::percent) +
scale_y_continuous(labels = scales::percent) +
labs(x = "P(Caucasian)", y = "P(African)")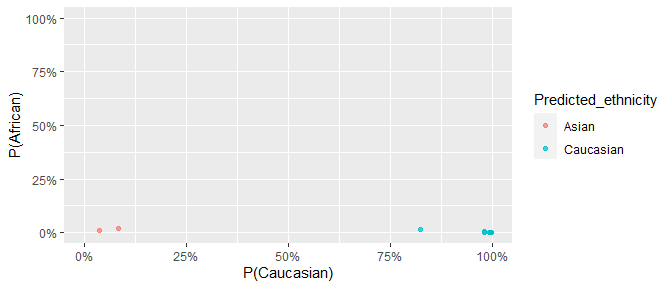
results %>%
ggplot(aes(
x = Prob_Caucasian, y = Prob_Asian,
col = Predicted_ethnicity
)) +
geom_point(alpha = 0.7) +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1)) +
scale_x_continuous(labels = scales::percent) +
scale_y_continuous(labels = scales::percent) +
labs(x = "P(Caucasian)", y = "P(Asian)")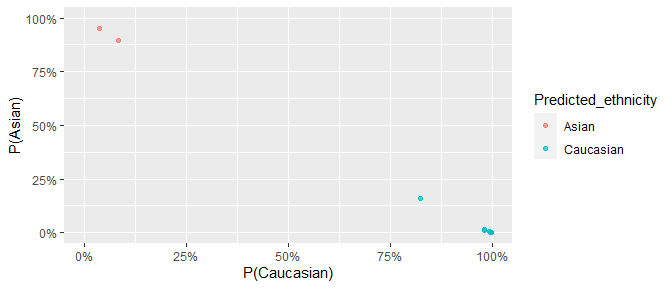
We can’t compare this to self-reported ethnicity as it is unavailable. But we know these samples were collected in Sydney, Australia, and are therefore likely mostly European with some East Asian participants.
table(results$Predicted_ethnicity)##
## Asian Caucasian
## 2 22A note on adjustment in differential methylation analysis
Because ‘Ambiguous’ samples might have different mixtures of ancestries, it might be inadequate to adjust for them as one group in an analysis of admixed populations (e.g. 50/50 Asian/African should not be considered the same group as 50/50 Caucasian/African). One solution would be to simply remove these samples. Another would be to adjust for the raw probabilities-in this case, use only two of the three probabilities, since the third will be redundant (probabilities sum to 1). If sample numbers are large enough in each group, stratifying downstream analyses by ethnicity might also be a valid option.
Session Info
## R version 4.3.2 (2023-10-31 ucrt)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 11 x64 (build 22631)
##
## Matrix products: default
##
##
## locale:
## [1] LC_COLLATE=English_United States.utf8
## [2] LC_CTYPE=English_United States.utf8
## [3] LC_MONETARY=English_United States.utf8
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.utf8
##
## time zone: America/Los_Angeles
## tzcode source: internal
##
## attached base packages:
## [1] parallel stats4 stats graphics grDevices utils datasets
## [8] methods base
##
## other attached packages:
## [1] planet_1.9.4 tidyr_1.3.1
## [3] ggplot2_3.4.4 dplyr_1.1.4
## [5] EpiDISH_2.18.0 minfi_1.48.0
## [7] bumphunter_1.44.0 locfit_1.5-9.8
## [9] iterators_1.0.14 foreach_1.5.2
## [11] Biostrings_2.70.2 XVector_0.42.0
## [13] SummarizedExperiment_1.32.0 Biobase_2.62.0
## [15] MatrixGenerics_1.14.0 matrixStats_1.2.0
## [17] GenomicRanges_1.54.1 GenomeInfoDb_1.38.6
## [19] IRanges_2.36.0 S4Vectors_0.40.2
## [21] BiocGenerics_0.48.1
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 rstudioapi_0.15.0
## [3] jsonlite_1.8.8 magrittr_2.0.3
## [5] GenomicFeatures_1.54.3 farver_2.1.1
## [7] rmarkdown_2.25 BiocIO_1.12.0
## [9] zlibbioc_1.48.0 vctrs_0.6.5
## [11] locfdr_1.1-8 multtest_2.58.0
## [13] memoise_2.0.1 Rsamtools_2.18.0
## [15] DelayedMatrixStats_1.24.0 RCurl_1.98-1.14
## [17] askpass_1.2.0 htmltools_0.5.7
## [19] S4Arrays_1.2.0 progress_1.2.3
## [21] curl_5.2.0 Rhdf5lib_1.24.2
## [23] SparseArray_1.2.4 rhdf5_2.46.1
## [25] sass_0.4.8 nor1mix_1.3-2
## [27] bslib_0.6.1 plyr_1.8.9
## [29] cachem_1.0.8 GenomicAlignments_1.38.2
## [31] lifecycle_1.0.4 pkgconfig_2.0.3
## [33] Matrix_1.6-1.1 R6_2.5.1
## [35] fastmap_1.1.1 GenomeInfoDbData_1.2.11
## [37] digest_0.6.34 colorspace_2.1-0
## [39] siggenes_1.76.0 reshape_0.8.9
## [41] AnnotationDbi_1.64.1 RSQLite_2.3.5
## [43] base64_2.0.1 labeling_0.4.3
## [45] filelock_1.0.3 fansi_1.0.6
## [47] mgcv_1.9-0 httr_1.4.7
## [49] abind_1.4-5 compiler_4.3.2
## [51] beanplot_1.3.1 proxy_0.4-27
## [53] rngtools_1.5.2 withr_3.0.0
## [55] bit64_4.0.5 BiocParallel_1.36.0
## [57] DBI_1.2.2 highr_0.10
## [59] HDF5Array_1.30.1 biomaRt_2.58.2
## [61] MASS_7.3-60 openssl_2.1.1
## [63] rappdirs_0.3.3 DelayedArray_0.28.0
## [65] rjson_0.2.21 tools_4.3.2
## [67] glue_1.7.0 quadprog_1.5-8
## [69] restfulr_0.0.15 nlme_3.1-163
## [71] rhdf5filters_1.14.1 grid_4.3.2
## [73] generics_0.1.3 gtable_0.3.4
## [75] tzdb_0.4.0 class_7.3-22
## [77] preprocessCore_1.64.0 data.table_1.15.0
## [79] hms_1.1.3 xml2_1.3.6
## [81] utf8_1.2.4 pillar_1.9.0
## [83] stringr_1.5.1 limma_3.58.1
## [85] genefilter_1.84.0 splines_4.3.2
## [87] BiocFileCache_2.10.1 lattice_0.21-9
## [89] survival_3.5-7 rtracklayer_1.62.0
## [91] bit_4.0.5 GEOquery_2.70.0
## [93] annotate_1.80.0 tidyselect_1.2.0
## [95] knitr_1.45 xfun_0.42
## [97] scrime_1.3.5 statmod_1.5.0
## [99] stringi_1.8.3 yaml_2.3.8
## [101] evaluate_0.23 codetools_0.2-19
## [103] tibble_3.2.1 cli_3.6.2
## [105] xtable_1.8-4 munsell_0.5.0
## [107] jquerylib_0.1.4 Rcpp_1.0.12
## [109] dbplyr_2.4.0 png_0.1-8
## [111] XML_3.99-0.16.1 readr_2.1.5
## [113] blob_1.2.4 prettyunits_1.2.0
## [115] mclust_6.0.1 doRNG_1.8.6
## [117] sparseMatrixStats_1.14.0 bitops_1.0-7
## [119] scales_1.3.0 e1071_1.7-14
## [121] illuminaio_0.44.0 purrr_1.0.2
## [123] crayon_1.5.2 rlang_1.1.2
## [125] KEGGREST_1.42.0